前端工程化
1. webpack 配置有哪些 ?
Webpack 的配置由多个关键部分组成,灵活运用这些配置可以满足不同项目的需求。
| 配置项 | 功能说明 |
|---|---|
| entry | 指定打包的入口文件,决定了 Webpack 从哪个模块开始生成依赖关系图。可以是单个或多个 JavaScript 文件。 |
| output | 设置打包后的输出目录和文件名,常用选项包括 path(输出目录)、filename(文件名)和 publicPath。 |
| module | 配置不同的 loaders 以处理各种类型的模块,例如对 CSS 文件使用 css-loader 和 style-loader。 |
| resolve | 设置模块解析方式,支持别名、扩展名等,方便引用模块。 |
| plugins | 使用不同插件扩展 Webpack 功能,例如 html-webpack-plugin 自动引用打包后的 JS 文件到 HTML 文件中。 |
| devServer | 配置开发服务器,支持实时重载功能,可以设置 devServer.contentBase、devServer.port、devServer.proxy。 |
| optimization | 配置优化策略,常用的有 optimization.splitChunks 代码拆分和 optimization.runtimeChunk 提取运行时代码。 |
| externals | 配置外部扩展模块,将特定模块排除出打包,例如将 jQuery 作为外部扩展以减少打包体积。 |
| devtool | 配置 source-map 类型,便于调试代码时查看错误的源文件位置。 |
| context | 设置 Webpack 使用的根目录,通常为绝对路径的字符串类型。 |
| target | 指定 Webpack 的编译目标环境,例如 web、node。 |
| performance | 配置文件的性能检查,确保输出文件体积在合理范围内。 |
| noParse | 配置不需要解析和处理的模块,减少构建时间。 |
| stats | 配置控制台的日志输出,便于分析构建信息。 |
这些配置项可以根据项目需求进行组合和调整,以便优化 Webpack 的打包效果和性能。
2. Webpack 常用 Loaders 和 Plugins
Loaders
Loaders 用于对模块的内容进行转换,支持对不同类型的文件(如 CSS、JS、图片等)进行处理。
| Loader | 功能说明 |
|---|---|
babel-loader | 将 ES6+ 的代码转换成 ES5 代码,兼容性处理。 |
css-loader | 解析 CSS 文件,并处理 CSS 文件中的依赖关系。 |
style-loader | 将 CSS 代码注入到 HTML 文档中,通常与 css-loader 搭配使用。 |
file-loader | 解析文件路径,将文件复制到输出目录中,并返回文件的路径。 |
url-loader | 类似于 file-loader,但可以将小于指定大小的文件转换为 Base64 编码的 Data URL。 |
sass-loader | 将 Sass 文件编译为 CSS 文件。 |
less-loader | 将 Less 文件编译为 CSS 文件。 |
postcss-loader | 自动为 CSS 添加前缀,并优化 CSS 代码。 |
vue-loader | 将 Vue 单文件组件编译为 JavaScript 代码。 |
Plugins
Plugins 用于扩展 Webpack 的功能,帮助实现自动化、优化、热更新等功能。
| Plugin | 功能说明 |
|---|---|
HtmlWebpackPlugin | 生成 HTML 文件,并自动引入打包后的 JavaScript 和 CSS 文件。 |
CleanWebpackPlugin | 在每次构建前清理输出目录,保持输出目录的整洁。 |
ExtractTextWebpackPlugin | 将 CSS 代码提取到单独的 CSS 文件中,减少 HTML 的嵌入样式代码。 |
DefinePlugin | 定义全局变量,方便在项目中注入环境变量或全局配置。 |
UglifyJsWebpackPlugin | 压缩 JavaScript 代码,通常在生产环境中使用。 |
HotModuleReplacementPlugin | 实现热模块替换,在开发环境下实现实时更新而不刷新页面。 |
MiniCssExtractPlugin | 将 CSS 代码提取到单独的 CSS 文件,作用类似于 ExtractTextWebpackPlugin。 |
BundleAnalyzerPlugin | 分析打包后的文件大小和依赖关系,帮助优化打包体积。 |
这些 Loaders 和 Plugins 是 Webpack 项目中常见的工具,可以根据具体需求配置和使用,以实现对文件的解析、优化和增强构建体验。
3. Webpack 中 Loader 和 Plugin 的区别
在 Webpack 中,Loader 和 Plugin 是两种不同的工具,功能和作用各不相同:
| 对比点 | Loader | Plugin |
|---|---|---|
| 作用 | 用于转换文件内容,使 Webpack 可以理解和处理非 JavaScript 文件类型(如 CSS、图片、TypeScript 等)。 | 用于扩展 Webpack 功能,进行复杂的打包优化、资源管理和环境变量注入等操作。 |
| 适用场景 | 处理特定文件类型,例如 css-loader 解析 CSS,babel-loader 编译 ES6+ 代码等。 | 实现构建流程优化、自动化功能,如 HtmlWebpackPlugin 自动生成 HTML,DefinePlugin 注入全局变量等。 |
| 使用方式 | 在 module.rules 中配置,通过 test 指定文件类型,并通过 use 使用相应的 loader。 | 在 plugins 数组中配置,直接实例化插件即可。 |
| 处理方式 | 针对单个文件逐个处理,作用于文件的内容层级。 | 可以访问 Webpack 编译的整个构建流程,在打包的各个阶段执行特定操作。 |
| 常见例子 | css-loader、style-loader、file-loader、babel-loader 等。 | HtmlWebpackPlugin、MiniCssExtractPlugin、DefinePlugin、HotModuleReplacementPlugin 等。 |
Webpack Plugin 的生命周期和广播事件
| 事件钩子 | 触发时机 |
|---|---|
environment | Webpack 环境设置完成,加载配置和插件。 |
afterEnvironment | 环境和插件设置完成后触发。 |
entryOption | 读取入口文件配置后触发。 |
afterPlugins | 插件加载完成后触发,已完成插件初始化。 |
afterResolvers | 解析器(Resolver)加载完成后触发,开始构建模块。 |
beforeRun | Webpack 构建启动之前触发。 |
run | 开始构建,第一次构建时触发。 |
watchRun | 监听模式启动时触发,用于监控文件变化的场景。 |
compile | 创建一个新的编译对象 Compilation 之前触发,进行准备工作。 |
compilation | 编译开始,生成新的编译对象 Compilation。此对象包含模块、资源、依赖等信息。 |
make | 从入口模块开始,构建模块依赖图时触发。 |
emit | 资源和代码已生成到内存,准备写入输出目录前触发,常用于生成额外的文件或修改输出内容。 |
afterEmit | 文件写入输出目录后触发,通常用于后续处理,如生成日志或通知。 |
done | 构建完成后触发,代表整个编译流程结束。 |
failed | 构建失败时触发。 |
invalid | 在监听模式下,文件发生更改时触发。 |
事件钩子示例
假设我们要创建一个插件,用于记录构建的开始和结束时间,可以利用 beforeRun 和 done 钩子来实现:
class BuildTimeLoggerPlugin {
apply(compiler) {
compiler.hooks.beforeRun.tap("BuildTimeLoggerPlugin", () => {
console.log("构建开始时间:", new Date());
});
compiler.hooks.done.tap("BuildTimeLoggerPlugin", () => {
console.log("构建结束时间:", new Date());
});
}
}
module.exports = BuildTimeLoggerPlugin;自定义 loader 示例:
// uppercase-loader.js
module.exports = function (source) {
// `source` 是文件内容的字符串
// 将文件内容转换为大写
const result = source.toUpperCase();
// 返回处理后的内容
return result;
};总结
- Loader:用于文件内容转换,帮助 Webpack 处理各种文件格式,使其能够被打包。
- Plugin:用于扩展 Webpack 功能,对构建过程进行控制和优化,提升打包效果。
合理配置 Loader 和 Plugin 可以更高效地利用 Webpack 构建项目。
4. 简单的说一下 webpack 的构建流程
1. 初始化(Initialization)
- Webpack 读取配置文件并合并默认配置、CLI 选项等,生成最终的配置对象。
- 根据配置创建
Compiler对象,并注册所有插件。
2. 编译(Compilation)
- 从
Entry(入口)文件出发,调用相应的 Loader 将不同类型的文件转换为 JavaScript 模块。 - 分析入口文件及其依赖关系,递归创建模块依赖图(Dependency Graph)。
3. 构建模块(Building Modules)
- 对依赖图中的每个模块进行递归解析,调用配置的 Loader 转换文件内容。
- 转换后的模块会加入到模块缓存中,避免重复构建相同模块。
4. 生成代码块(Chunking)
- 根据配置,将模块分组为不同的
Chunk(代码块),如main、vendor、runtime等。 - 使用
optimization.splitChunks选项来优化代码块,进行代码拆分以实现按需加载和缓存优化。
5. 输出(Emitting)
- 将所有代码块(Chunk)转换成文件,包含最终的 JavaScript、CSS 等静态资源文件。
- Webpack 会调用
emit钩子,允许插件在输出文件到目标目录之前进行最后的修改。 - 最终,Webpack 将生成的文件写入到输出目录(如
dist)。
6. 完成(Finish)
- 完成构建流程,触发
done钩子,记录构建状态或生成日志等。
Webpack 构建流程的简要总结
| 阶段 | 描述 |
|---|---|
| 初始化 | 读取配置并创建 Compiler 对象,注册插件和插件的生命周期钩子。 |
| 编译 | 从入口文件解析依赖,递归创建依赖图,将文件转换成模块。 |
| 构建模块 | 调用 Loader 解析和转换每个模块的内容。 |
| 生成代码块 | 分组模块形成代码块,根据配置拆分代码块用于按需加载和缓存优化。 |
| 输出 | 将代码块转换成文件并写入输出目录,触发 emit 钩子以便插件做进一步处理。 |
| 完成 | 构建结束,触发 done 钩子。 |
配置解析 → 初始化 Compiler → 编译依赖图 → 模块构建 → 生成代码块 → 输出文件
5. 什么是 webpack 的热更新HMR ?原理是什么?
Webpack 的热更新,在不刷新页面的前提下,将新代码替换掉旧代码。
HRM 的原理实际上是 webpack-dev-server(WDS)和浏览器之间维护了一个 websocket 服务。当本地资源发生变化后,webpack 会先将打包生成新的模块代码放入内存中,然后 WDS 向浏览器推送更新,并附带上构建时的 hash,让客户端和上一次资源进行对比.
6. webpack 中 如何 Code Splitting ?
什么是 Code Splitting(代码分割)
Code Splitting(代码分割)是将应用程序的代码拆分为多个文件(chunks),使浏览器能够按需加载这些文件,而不是一次性加载所有代码。这样可以显著减少初始加载的文件大小,提高网站或应用的加载速度和响应性能,尤其是在大型应用中。
Code Splitting 的类型
入口点分割(Entry Points)
- 根据不同的入口文件生成多个输出文件。这种方式适用于多页面应用(MPA),每个页面有独立的入口文件。
动态导入(Dynamic Imports)
- 使用
import()函数动态加载模块。在需要时加载特定的模块,而不是在应用启动时就加载所有模块。这适用于单页面应用(SPA),如按需加载模块或路由模块。
- 使用
共享模块分割(Shared Chunks)
- 提取多个入口文件中共享的模块,将其拆分成一个单独的代码块,避免重复加载相同的模块。例如,将多个页面或模块共享的依赖提取为公共模块。
手动控制分割(Manual Split)
- 通过配置 Webpack 的
cacheGroups和splitChunks来手动分割代码块。例如,可以手动将node_modules中的第三方库提取为单独的文件。
- 通过配置 Webpack 的
Code Splitting 的好处
- 提高加载速度:只加载当前需要的文件,减少初始加载的文件大小。
- 按需加载:避免不必要的模块加载,提升页面响应速度。
- 缓存优化:将共享的代码提取为独立的文件,不会因为应用程序代码的变化而重新加载,提高缓存利用率。
Code Splitting 的实现方式
- Webpack 提供了多种方式来实现代码分割,包括入口点分割、动态导入、共享模块提取等,可以根据不同的应用场景选择合适的方案。
总结
Code Splitting 是 Webpack 提供的强大功能,它能够将应用代码拆分为多个块,按需加载,从而提升应用的性能。合理使用 Code Splitting 可以有效减少初始加载时间,提高用户体验。
7.Webpack 的 Source Map 是什么?如何配置生成 Source Map?
Webpack 的 Source Map
Source Map 是一种工具,用于将经过转换或压缩后的代码映射回原始的源代码,主要用于调试。在代码经过压缩、转换或打包后,调试时我们通常无法直接理解压缩后的代码,而是通过 Source Map 来帮助我们将错误和调试信息映射到原始源代码。
Source Map 的作用
- 调试:让开发者在浏览器开发者工具中查看原始代码,便于调试和定位问题。
- 错误追踪:当应用发生错误时,Source Map 能帮助开发者查看源代码中的出错位置,而不是被压缩后的代码。
- 保留代码结构:在生产环境中,虽然使用了压缩后的代码,但通过 Source Map 仍然能查看和调试原始的代码结构。
Webpack 中的 Source Map 配置
在 Webpack 中,配置 devtool 来指定如何生成 Source Map。不同的配置会影响生成的 Source Map 的质量、速度和调试体验。以下是常用的 devtool 配置:
常见的 devtool 配置
source-map:用于生产环境,生成独立的.map文件,包含完整的源代码映射。适合需要高精度调试的场景。cheap-source-map:生成简单的 Source Map,适用于需要更高构建速度的环境。丢失列信息,只有文件级别的映射。eval-source-map:适用于开发环境,生成快速的 Source Map,且以eval形式嵌入到打包后的文件中。适合快速构建和调试。inline-source-map:将 Source Map 嵌入到生成的文件中,而不是生成独立的.map文件。适用于开发环境,避免管理单独的 Source Map 文件。hidden-source-map:生成 Source Map 文件,但不会暴露给浏览器。适用于生产环境,避免泄露源代码信息。cheap-module-source-map:适用于调试通过模块转换(如 Babel)后的代码,生成速度较快,适用于开发环境。
Source Map 的配置选择
- 开发环境:通常选择生成速度较快、能即时查看调试信息的配置,如
eval-source-map或inline-source-map。 - 生产环境:通常选择
source-map或hidden-source-map,以确保能追踪源代码中的错误,同时避免暴露过多源代码信息。
总结
Source Map 是 Webpack 提供的一个重要调试工具,可以帮助开发者在调试过程中轻松查看源代码,准确定位错误。通过合理配置 devtool,可以根据开发或生产环境的需要选择适合的 Source Map 配置,提升开发效率和调试体验。
8. Webpack 的 Tree Shaking 原理
Tree Shaking 是 Webpack 提供的一项优化技术,旨在去除 JavaScript 代码中未使用的部分,减小打包后的文件体积,提高加载性能。它的核心思想是通过分析模块之间的依赖关系,自动删除那些没有被引用的代码,避免不必要的代码被打包和发送到浏览器。
Tree Shaking 的工作原理
ES6 模块的静态结构:Tree Shaking 的有效性依赖于 ES6 模块(
import/export)的静态结构。与 CommonJS 的动态require()语法不同,ES6 模块在编译时能够明确识别出哪些导入和导出是实际需要的,这为 Tree Shaking 提供了基础。死代码消除:Webpack 会根据代码中哪些导入的模块被实际使用,去除那些没有被引用的代码。这些未使用的代码被认为是“死代码”,通过 Tree Shaking 可以从最终的输出中剔除。
标记未使用的代码:Webpack 会通过静态分析(AST,抽象语法树)对代码进行分析,标记哪些导入的模块没有被使用,然后在打包时剔除这些模块。ES6 的
import/export语法使得这一过程变得可行和高效。优化生产环境:Tree Shaking 主要在生产环境下生效,默认情况下,Webpack 会在构建时剔除未使用的代码,这样最终打包出来的代码会更小,加载速度也更快。
Tree Shaking 的使用条件
使用 ES6 模块:Tree Shaking 只适用于 ES6 模块(
import/export),因为它们的依赖关系是静态的。CommonJS 模块(require)是动态加载的,Webpack 无法在编译时静态分析它们的依赖关系,因此无法进行 Tree Shaking。启用生产模式:Webpack 在
production模式下默认启用 Tree Shaking。这是因为 Webpack 在生产模式下会开启一系列优化(如压缩、死代码消除等)。没有副作用的代码:Tree Shaking 会依赖于模块是否有副作用。副作用是指执行某个模块时会影响到其他模块的状态,或者执行全局操作。Webpack 通过
package.json中的sideEffects字段来判断模块是否有副作用。若sideEffects字段为false,表示该模块可以进行 Tree Shaking。
配置 Tree Shaking
生产环境:在
webpack.config.js中,将mode设置为production,Webpack 会自动启用 Tree Shaking。javascriptmodule.exports = { mode: "production", // 启用生产模式,会自动开启 Tree Shaking };
- 如何提高 webpack 的打包速度
- 利用缓存: 利用 Webpack 的持久缓存功能,避免重复构建没有变化的代码
- 使用多进程/多线程构建: 使用 thread-loader、happypack 等插件可以将构建过程分解为多个进程或线程
- 使用 DllPlugin 和 HardSourceWebpackPlugin: DllPlugin 可以将第三方库预先打包成单独的文件,减少构建时间。HardSourceWebpackPlugin 可以缓存中间文件,加速后续构建过程
- 使用 Tree Shaking: 配置 Webpack 的 Tree Shaking 机制,去除未使用的代码,减小生成的文件体积
- 移除不必要的插件: 移除不必要的插件和配置,避免不必要的复杂性和性能开销
- 仅对必要文件使用 loader: 不打包
node_modules下的文件
9. 为什么vite 打包比webpack 快
Vite 比 Webpack 快在哪里?
Vite 是一个现代化的前端构建工具,旨在提供快速的开发体验和高效的构建速度。相比于 Webpack,Vite 在多个方面优化了性能,主要体现在以下几个方面:
1. 基于原生 ES 模块的开发模式
Vite 采用了原生的 ES 模块(ESM)作为开发过程中的模块加载机制,而 Webpack 使用的是传统的模块打包方式。
优势:
- 无需打包:在开发模式下,Vite 会将源代码按需加载,而不是像 Webpack 那样将所有代码打包到一个大文件中。这意味着,Vite 在启动时几乎没有打包过程,开发者可以立即开始开发。
- 按需加载:只在需要时加载和转换代码,避免了冗余的模块和代码。
2. 极速的热模块替换(HMR)
Vite 的热模块替换(HMR)比 Webpack 更加高效。它利用了浏览器对 ES 模块的原生支持,只需更新有变化的模块,而不需要重新加载整个应用程序。
优势:
- 更快的模块替换:由于 Vite 使用的是原生模块,HMR 的更新速度非常快,通常比 Webpack 更快,能够更快地反映代码改动。
- 更低的刷新成本:Vite 的 HMR 更新仅传递变更的部分,而不是重新构建整个项目。
3. 按需构建(即时构建)
Vite 使用了现代浏览器的原生特性,构建过程基于 即时构建(On-Demand Build),即每个模块的代码只有在需要时才会被编译,而 Webpack 则需要在初始化时将整个项目打包。
优势:
- 冷启动速度快:Vite 在启动时不需要构建整个项目,只加载和编译当前需要的模块,从而大大加快了启动速度。
- 热更新更迅速:修改代码时,Vite 只编译被修改的模块,不需要重新编译整个项目。
4. 使用 Rollup 进行生产构建
Vite 在生产构建时使用 Rollup 作为打包工具,而 Webpack 使用其自有的打包机制。Rollup 本身在处理现代 JavaScript 库时优化得很好,特别是在做 Tree Shaking 和代码拆分方面。
优势:
- 更高效的 Tree Shaking:Rollup 提供了比 Webpack 更高效的 Tree Shaking,可以删除更多未使用的代码,减小打包体积。
- 更快的生产构建:由于 Rollup 的高效打包和优化机制,Vite 在构建生产环境代码时通常比 Webpack 更快。
5. 更轻量级的配置
Vite 的配置非常简洁,默认配置即适用于大多数项目,而 Webpack 的配置则相对复杂,需要更多的手动调整和插件配置。
优势:
- 开箱即用:Vite 提供了默认的配置,能够快速启动项目,而 Webpack 往往需要更多的时间进行配置和调整。
- 更少的配置复杂度:Vite 简化了开发者的配置工作,特别是对于大多数前端开发需求,Vite 不需要像 Webpack 那样做大量的配置。
6. 利用浏览器的原生支持
Vite 在开发过程中通过原生的 ES 模块支持,利用现代浏览器的功能(如动态导入、原生模块加载)来避免传统打包工具中的一些性能瓶颈。
优势:
- 不需要打包:Vite 的开发服务器只会处理需要的模块,避免了 Webpack 在开发时对整个应用程序的重打包。
- 更少的依赖和插件:Vite 提供的默认支持可以直接处理大部分前端开发需求,减少了对插件和依赖的依赖,从而降低了复杂性和构建时间。
7. 自动优化和智能预构建
Vite 通过预构建第三方依赖(使用 esbuild)来进一步加速启动时间。它会在启动时自动预构建项目中使用的第三方库,并将这些库缓存起来以提高后续启动和热更新的速度。
优势:
- 第三方依赖预构建:在 Vite 中,常用的第三方依赖(如 Vue、React 等)会被 esbuild 预构建和缓存,这样可以避免每次启动时都重新处理这些依赖。
- 加速依赖解析:Vite 利用 esbuild 快速解析和打包第三方库,比 Webpack 的处理方式要高效得多。
总结
Vite 相较于 Webpack 在以下几个方面具有明显优势:
- 更快速的启动和热更新:基于原生 ES 模块,避免了不必要的打包。
- 更高效的生产构建:使用 Rollup 优化了 Tree Shaking 和代码拆分。
- 更轻量的配置和开发体验:Vite 提供开箱即用的配置,简化了开发过程。
因此,Vite 在开发过程中提供了更高的性能,特别是在大规模项目和复杂应用的构建上,Vite 的效率和快速反馈体验是 Webpack 所无法比拟的。
10. Vite, Webpack, Rspack 等打包工具的对比
随着前端开发的不断发展,越来越多的构建工具和打包工具涌现出来。Vite、Webpack 和 Rspack 是目前广泛使用的几种打包工具,它们在构建速度、配置复杂度、功能扩展等方面有各自的优势和特点。下面是它们之间的对比:
1. 构建速度
| 工具 | 开发模式构建速度 | 生产模式构建速度 | 说明 |
|---|---|---|---|
| Vite | 极快 | 较快 | Vite 使用原生的 ES 模块,支持按需构建,利用 esbuild 提供极速构建。 |
| Webpack | 较慢 | 较慢 | Webpack 在开发模式下需要重新打包整个项目,且生产构建需要复杂配置。 |
| Rspack | 快 | 更快 | Rspack 基于 Rust 开发,利用并行和优化算法大幅提升构建速度。 |
总结:
- Vite 提供了极快的开发模式启动速度,依赖原生 ES 模块和按需加载。
- Webpack 的构建速度较慢,尤其在大型项目中可能需要较长时间的打包过程。
- Rspack 是一个新的工具,主打更高效的构建速度,采用 Rust 实现,针对构建速度做了很多优化。
2. 配置复杂度
| 工具 | 配置复杂度 | 说明 |
|---|---|---|
| Vite | 低 | Vite 的默认配置简洁,通常不需要过多的配置即可上手使用。 |
| Webpack | 高 | Webpack 的配置复杂,需要根据项目的不同需求进行详细配置。 |
| Rspack | 低 | Rspack 也提供了类似于 Vite 的简洁配置,配置上和 Webpack 相比更简单。 |
总结:
- Vite 和 Rspack 都提供了简洁的配置,开箱即用。
- Webpack 的配置复杂且需要大量的定制,适用于有复杂需求的项目。
3. 插件生态
| 工具 | 插件生态 | 说明 |
|---|---|---|
| Vite | 中等 | Vite 的插件生态正在快速发展,但相比 Webpack 还有差距。 |
| Webpack | 极其丰富 | Webpack 拥有庞大的插件生态,可以满足各种需求。 |
| Rspack | 新兴 | Rspack 插件生态正在逐步发展,但目前相对较小。 |
总结:
- Webpack 拥有最成熟和丰富的插件生态,能够支持各种需求。
- Vite 和 Rspack 的插件生态还在发展中,虽然越来越完善,但可能在某些特定需求上不如 Webpack 强大。
4. 使用场景
| 工具 | 最适用场景 | 说明 |
|---|---|---|
| Vite | 中小型项目,快速开发 | Vite 提供了快速的构建和开发体验,适合开发快速迭代的项目。 |
| Webpack | 大型复杂项目,企业级应用 | Webpack 可以处理复杂的需求,适合大规模项目或需要深度定制的应用。 |
| Rspack | 高性能要求的项目 | Rspack 主要关注性能,适合需要更快构建和高效构建速度的项目。 |
总结:
- Vite 适合快速开发和构建速度要求较高的项目,特别是中小型项目。
- Webpack 更适合大型项目和需要复杂配置的企业级应用。
- Rspack 针对需要高性能的项目,尤其在构建速度方面有明显优势。
5. 支持的特性
| 工具 | 支持的特性 | 说明 |
|---|---|---|
| Vite | 热模块替换(HMR),按需构建,ESM,TypeScript 等 | 支持原生 ES 模块,按需构建和极速热更新。 |
| Webpack | 热模块替换(HMR),代码分割,Tree Shaking 等 | 支持模块化开发,灵活的代码分割和优化机制。 |
| Rspack | 热模块替换(HMR),更高效的构建优化,代码分割等 | 提供高效的构建流程和优化,尤其在大规模项目中表现优异。 |
总结:
- Vite 在支持现代 JavaScript 特性方面表现优异,适合开发现代前端应用。
- Webpack 提供了更加完善的功能,特别是在支持复杂特性和深度定制方面。
- Rspack 提供了更高效的构建体验,尤其是针对大型项目的性能优化。
总结
| 工具 | 速度 | 配置 | 插件生态 | 最适用场景 |
|---|---|---|---|---|
| Vite | 快 | 低 | 中等 | 中小型项目,快速开发 |
| Webpack | 较慢 | 高 | 极其丰富 | 大型复杂项目,企业级应用 |
| Rspack | 极快 | 低 | 新兴 | 高性能要求的项目 |
总结:
- Vite 适合现代 Web 开发,尤其是在开发速度和热更新方面表现突出。
- Webpack 是成熟的解决方案,适用于复杂项目和企业级应用,但配置较为繁琐。
- Rspack 作为新兴工具,聚焦于极致的构建性能,适合追求极高构建速度的项目。
11. 说一下你对 Monorepo 的理解
12. Monorepo 实现方式及工具对比
在现代前端和后端开发中,Monorepo(单一代码仓库)是一个非常流行的做法,尤其是在大型团队或多项目协作的情况下。Monorepo 是将多个相关的项目或模块存放在同一个代码仓库中,并通过一些工具进行管理和构建。它能够提高代码共享、版本管理、CI/CD 流程以及依赖管理的效率。
如何在项目中实现 Monorepo?
在项目中实现 Monorepo 通常会用到一些构建工具来帮助管理代码的依赖和版本控制。以下是一些常见的做法:
1. 使用 Lerna 管理依赖
- Lerna 是一个常见的 Monorepo 管理工具,它可以帮助你管理多个包、处理跨包的依赖关系,并通过命令行工具来运行跨包操作。Lerna 支持自动化发布流程、版本管理等。
- 常见配置:通过
lerna.json文件定义工作区,配置版本策略(独立版本或固定版本)。
2. 使用 Yarn Workspaces
- Yarn Workspaces 是 Yarn 提供的一种内置特性,可以让多个包共用同一个
node_modules目录,避免重复依赖,提高构建效率。它适合用于包含多个 JavaScript 包的 Monorepo。 - 常见配置:在
package.json中配置workspaces字段,指定工作空间范围。
3. 使用 Nx
- Nx 是一个由 Nrwl 团队开发的 Monorepo 管理工具,特别适用于大型企业级应用。Nx 提供了更丰富的功能,如缓存、依赖图分析、构建优化等。
- 常见配置:通过
nx.json配置工作区、设置不同的构建和部署策略。
4. 使用 Rush.js
- Rush.js 是一个面向企业级项目的 Monorepo 管理工具,它提供了更加高效的依赖管理、构建和发布流程,特别是在处理大量包和模块时。
- 常见配置:通过
rush.json配置工作区,设置版本控制、构建流水线等。
市面上常见的 Monorepo 管理工具对比
| 工具 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| Lerna | 支持多个 JavaScript 包的管理,自动化发布工具 | 1. 简单易用,配置灵活。 2. 支持独立版本和固定版本。 | 1. 功能相对简单,适合中小型项目。 2. 不支持更多高级特性。 |
| Yarn Workspaces | 由 Yarn 提供的内置功能,简化依赖管理 | 1. 与 Yarn 集成,易于配置和使用。 2. 节省磁盘空间,避免重复安装依赖。 | 1. 对大型项目的构建优化有限。 2. 在某些复杂场景下不易扩展。 |
| Nx | 基于 Angular 构建的企业级 Monorepo 管理工具 | 1. 丰富的功能,如缓存、构建优化和依赖分析。 2. 支持多种框架(React、Vue、Angular)。 | 1. 配置较为复杂,入门门槛较高。 2. 对小型项目可能过于复杂。 |
| Rush.js | 企业级 Monorepo 管理工具,注重性能和构建流水线 | 1. 处理大型项目非常高效。 2. 提供对 CI/CD 流程的良好支持。 | 1. 配置复杂,学习成本较高。 2. 只适合大规模项目。 |
总结
- Lerna 和 Yarn Workspaces 适合中小型项目,能够帮助团队高效地管理依赖,发布新版本。
- Nx 更适合大型企业级应用,尤其是在需要构建优化、缓存和依赖分析等高级功能时。
- Rush.js 适合有大量包和复杂构建需求的大型企业项目,能够提供更高的构建效率和 CI/CD 流程支持。
Monorepo 提供了集中式管理和协作的优势,但在配置、依赖管理和构建优化上都有一定的挑战。选择适合团队规模和项目需求的工具至关重要。
13. 为什么 pnpm 比 npm 快
Pnpm 使用基于内容寻址的文件系统来存储磁盘上的所有文件,这意味着它不会在磁盘中重复存储相同的依赖包,即使这些依赖包被不同的项目所依赖。这种存储方式使得 Pnpm 在安装依赖时能够更高效地利用磁盘空间,同时也减少了下载和安装的时间。
14. npm pnpm yarn 和 npx 对比
| 特性 | npm | pnpm | yarn | npx |
|---|---|---|---|---|
| 介绍 | Node.js 的官方包管理工具 | 高效的包管理工具,使用硬链接机制 | Facebook 提供的替代 npm 的工具 | 用于运行 Node.js 包,类似命令行工具 |
| 安装速度 | 较慢,依赖每次都安装,使用递归嵌套 | 更快,通过硬链接共享依赖,避免重复安装 | 较快,支持并行下载、缓存优化 | 不涉及安装,运行时临时下载和执行命令 |
| 磁盘空间占用 | 每个项目都有独立的 node_modules | 节省磁盘空间,依赖共享(硬链接) | 与 npm 类似,单项目存储 node_modules | 无需磁盘占用,临时执行命令 |
| 并行下载 | 支持并行下载,但优化不如 pnpm 和 yarn | 支持高效的并行下载 | 支持并行下载,优化较好 | 无并行下载,执行时即时获取 |
| 锁文件 | 使用 package-lock.json | 使用 pnpm-lock.yaml | 使用 yarn.lock | 无锁文件概念,临时执行命令 |
| 去重依赖 | 去重机制一般,可能有重复依赖 | 依赖去重更智能,避免重复 | 去重机制较好,依赖树优化 | 无依赖去重问题,临时执行命令 |
| 命令兼容性 | 与 npm 脚本兼容,支持所有 npm 命令 | 与 npm 命令兼容 | 兼容 npm 命令 | 无需安装包,直接运行包中的命令 |
| 网络请求优化 | 较慢,依赖每次下载 | 优化了下载依赖的网络请求 | 比 npm 更快,优化网络请求 | 不涉及网络请求,直接临时下载 |
| 使用场景 | 广泛使用,默认的 Node 包管理工具 | 适用于需要提高构建速度和节省空间的项目 | 适用于需要更快安装和更好缓存的项目 | 用于临时执行一个包中的命令 |
| 跨平台支持 | 跨平台支持较好 | 跨平台支持较好 | 跨平台支持较好 | 跨平台支持较好 |
| 适用的开发环境 | 通用,适用于各种项目 | 适合大规模应用,尤其是 Monorepo 项目 | 适合中到大型项目,特别是 React 开发 | 临时执行任何 npm 包中的命令 |
详细对比
npm
- 官方工具,默认安装在 Node.js 中。
- 安装速度相对较慢,特别是在安装大量依赖时,由于没有像 pnpm 那样的硬链接机制,每个项目都要重复安装依赖。
- 支持并行安装,但在优化方面不如 pnpm 和 yarn。
- 使用
package-lock.json锁定依赖版本,确保跨环境的一致性。
pnpm
- 高效的包管理工具,通过硬链接实现依赖共享,减少磁盘空间使用,提高安装速度。
- 去重机制:依赖版本冲突的情况下,使用更智能的方式减少重复依赖。
- 安装速度非常快,特别适用于大规模应用和 Monorepo 项目。
yarn
- Facebook 提供的工具,提升了 npm 的功能,支持更快的安装速度和优化的缓存机制。
- 具有 并行安装 和 缓存优化,使得它比 npm 更快。
- yarn.lock 锁定依赖,确保一致性。
- 对于 React 和其他 JavaScript 项目特别流行,尤其是在 Facebook 的支持下,它有强大的生态系统。
npx
- 临时执行命令:无需事先安装包,直接执行在
node_modules或通过 npm 注册的包中的命令。 - 比如,执行一个全局包的命令(如
create-react-app),npx 会自动下载并执行,而不需要你全局安装该包。 - 适用于临时使用某些命令行工具,避免了全局安装带来的管理麻烦。
总结
- npm 是默认的包管理工具,适合大多数项目,但在性能上相对较慢。
- pnpm 通过硬链接和去重机制,提供了更高的性能和更高效的磁盘使用,适合大型项目或 Monorepo 构建。
- yarn 提供了与 npm 类似的功能,但优化了缓存和并行下载,性能上比 npm 更好,适合中到大型项目。
- npx 是一个命令行工具,用于执行 Node.js 包的命令,临时下载和执行,无需安装,适合临时需求。
pnpm 优势:
- pnpm 通过使用硬链接、平铺依赖、并行下载、优化缓存和依赖去重等机制,使得包管理过程更高效,安装速度更快,磁盘空间的使用更合理。
- npm 在这些方面的优化较少,导致它的安装速度通常较 pnpm 慢。
15. ESLint 概念及原理
什么是 ESLint?
ESLint 是一个用于识别和报告 JavaScript 代码中的问题(如语法错误、潜在错误、代码风格不一致等)的工具。它可以帮助开发人员在编写代码时就发现潜在的错误,并保持一致的编码风格。ESLint 是一个可配置的工具,可以根据项目的需求定制规则,以确保代码质量和可维护性。 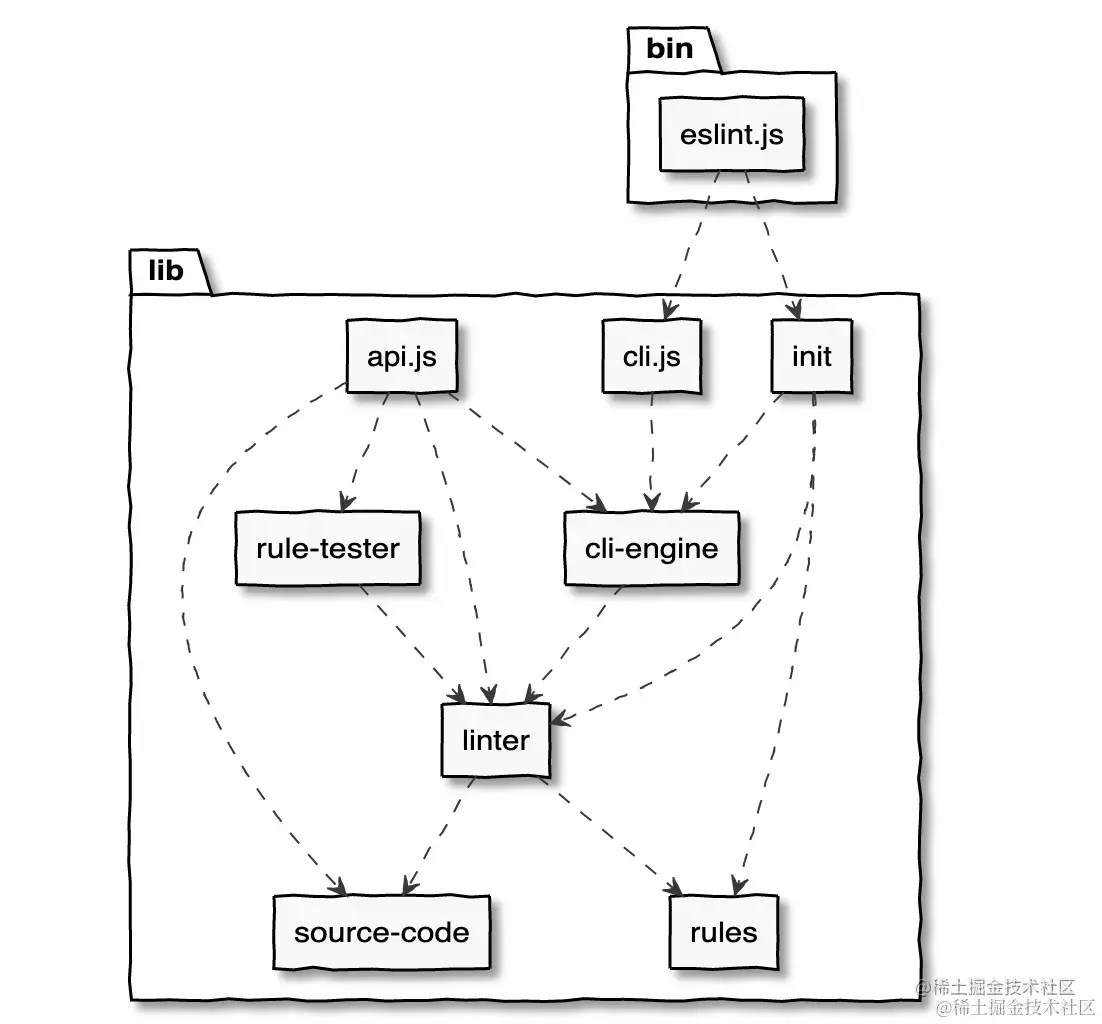
ESLint 的主要功能
语法检查:
- ESLint 可以检测 JavaScript 代码中的语法错误,如拼写错误、未定义的变量等。
代码风格检查:
- ESLint 支持配置各种规则,检查代码是否符合团队的编码风格,比如变量命名、缩进方式、分号使用等。
潜在错误检测:
- ESLint 可以识别潜在的代码问题,例如空函数、冗余代码、不必要的循环等。
自动修复:
- ESLint 提供了
--fix命令,自动修复某些类型的代码风格问题,如多余的空格、不一致的缩进等。
- ESLint 提供了
ESLint 的原理
ESLint 的工作原理可以概括为以下几个步骤:
1. 解析阶段(Parsing)
ESLint 首先会将 JavaScript 代码解析成抽象语法树(AST)。AST 是一种以树状结构表示代码的方式,每个节点代表代码中的一个元素(如变量、函数、表达式等)。ESLint 使用 Espree(基于 Acorn 的 JavaScript 解析器)将代码转化为 AST。
2. 规则检查(Linting)
在解析完代码后,ESLint 会根据配置的规则对 AST 进行遍历,检查代码是否符合规则。每个规则对应一个算法,用来检查 AST 中的节点是否满足预期的编码要求。
3. 报告问题
ESLint 会生成报告,列出代码中违反的规则及其所在的位置。报告的内容包括文件名、行号、列号、问题的类型等,方便开发者进行修改。
4. 自动修复(如果支持)
对于某些规则,ESLint 提供了自动修复功能,开发者可以使用 --fix 命令自动修复可修复的问题。例如,统一的空格、换行符、分号等。
ESLint 配置文件
ESLint 配置文件是 ESLint 的核心部分之一,它用来指定项目中所使用的规则、环境、插件等。配置文件通常有三种格式:
.eslintrc.json:JSON 格式的配置文件。.eslintrc.yaml:YAML 格式的配置文件。.eslintrc.js:JavaScript 格式的配置文件。
ESLint 配置文件一般包括以下几部分:
- env:指定代码的运行环境,如
browser、node、es6等。 - extends:扩展一些预设规则集,可以继承一组通用的规则(如
eslint:recommended)。 - plugins:指定使用的 ESLint 插件,插件可以提供额外的规则或配置。
- rules:配置具体的规则及其级别(
off、warn、error)。
常见规则
ESLint 提供了丰富的规则,以下是一些常见的规则:
- semi:要求或禁止使用分号,设置为
["error", "always"]可以强制每个语句结束时使用分号。 - quotes:规定字符串的引号样式,设置为
["error", "single"]可以强制使用单引号。 - no-unused-vars:禁止未使用的变量。
- no-console:禁止使用
console,可以防止开发环境中不小心留下console.log。 - eqeqeq:强制使用严格等号(
===)而不是宽松等号(==)。 - indent:规定缩进方式
16. Babel 概念及原理
什么是 Babel?
Babel 是一个广泛使用的 JavaScript 编译工具,主要用于将现代 JavaScript(如 ES6+)代码转换为向后兼容的 JavaScript 代码,使其能够在旧版本的浏览器或运行环境中运行。它不仅仅支持 JavaScript 的新语法,还可以转换 TypeScript、JSX 等语言特性,极大地提升了开发体验和代码兼容性。
Babel 的核心功能
语法转换(Syntax Transformation): Babel 最重要的功能是将现代 JavaScript 代码转换为向后兼容的代码。例如,ES6 的箭头函数、类、模板字符串、解构等语法,可以通过 Babel 转换为 ES5 或其他更广泛支持的版本。
JSX 转换: Babel 也支持将 JSX 语法(React 的一种语法扩展)转换为常规的 JavaScript 函数调用。JSX 语法在浏览器中并不被原生支持,需要通过 Babel 转换。
TypeScript 支持: Babel 可以直接处理 TypeScript 代码,并将其转换为 JavaScript。虽然 Babel 并不会进行类型检查(这需要 TypeScript 编译器),但它可以将 TypeScript 转换为 ES5 或其他 JavaScript 标准。
插件机制: Babel 支持插件机制,开发者可以根据需要选择适合的插件,进一步定制转码的行为。例如,可以使用插件来支持新的 ECMAScript 提案,或者添加代码优化等。
Babel 的工作原理
Babel 的工作原理分为三个主要的阶段:
1. 解析(Parsing)
Babel 首先会对输入的 JavaScript 代码进行解析,将其转化为 抽象语法树(AST)。抽象语法树是对代码结构的一种树形表示,每个节点代表代码中的一个元素(如变量、运算符、函数等)。
Babel 使用的解析器是 Babylon,它支持最新的 ECMAScript 语法和一些实验性的语法。
2. 转换(Transformation)
在这个阶段,Babel 会根据指定的插件和预设,对抽象语法树进行转换。Babel 会遍历 AST,根据配置规则将 AST 中的新语法(如箭头函数、类、async/await 等)转换为兼容的老版本 JavaScript 语法(如 function、var、callback 等)。
例如,箭头函数(() => {})会被转换为传统的匿名函数表达式。
3. 代码生成(Code Generation)
最后,Babel 会将转换后的 AST 转换回 JavaScript 代码,生成目标代码。这个阶段的输出就是浏览器可以运行的 JavaScript 代码。
在这个阶段,Babel 会生成最终的代码,确保语法上的兼容性,并通过适当的配置处理代码优化。
Babel 的主要组件
Parser(解析器): 负责将源代码解析为 AST。解析器使用 Babel 提供的
@babel/parser,支持最新的 JavaScript 语法。Plugins(插件): 插件是 Babel 的核心,可以在转换过程中对 AST 进行修改。每个插件实现特定的功能,例如,转换箭头函数、类、异步函数等。通过组合多个插件,Babel 可以支持复杂的转换任务。
Presets(预设): 预设是 Babel 插件的集合,帮助用户快速配置常见的转换规则。比如,
@babel/preset-env是一个预设,包含了将最新的 ECMAScript 特性转换为 ES5 的插件集合,适用于浏览器兼容性转换。Babel CLI: Babel 提供了命令行工具,可以直接在命令行中使用 Babel 进行代码转换。开发者可以使用
babel命令,传入需要转换的文件,输出转换后的代码。
Babel 配置文件
Babel 配置文件通常为 .babelrc 文件或 babel.config.js 文件,用于指定 Babel 的行为。常见的配置项包括:
- presets:指定要使用的预设,预设是一组插件的集合。例如,
@babel/preset-env、@babel/preset-react等。 - plugins:指定要使用的单独插件,插件用于对代码进行具体的转换操作。例如,
@babel/plugin-transform-arrow-functions用于转换箭头函数。 - env:指定不同环境下的配置。例如,可以为生产环境和开发环境配置不同的转码规则。
Babel 常见插件
@babel/plugin-transform-arrow-functions:将箭头函数转换为传统的匿名函数。@babel/plugin-transform-classes:将 ES6 类转换为 ES5 函数构造器。@babel/plugin-transform-async-to-generator:将async/await转换为生成器函数。@babel/plugin-proposal-class-properties:支持类属性的语法。
Babel 常见预设
- @babel/preset-env:根据目标环境(如浏览器或 Node.js 版本)自动选择适当的 Babel 插件,转换代码中的新特性。
- @babel/preset-react:用于将 React 的 JSX 语法转换为普通的 JavaScript 代码。
- @babel/preset-typescript:支持 TypeScript 代码的转换。
总结
Babel 是一个功能强大的 JavaScript 转译工具,它可以将现代 JavaScript 代码转换为兼容旧版浏览器或环境的代码,支持多种语言特性(如 JSX、TypeScript)。通过插件和预设,Babel 提供了灵活的配置选项,满足不同开发需求。它的工作原理包括解析、转换和代码生成三个阶段,广泛应用于前端开发中,尤其是对于需要兼容多个浏览器的项目。 Babel 概念及原理
17. npm install 的执行过程
npm install 是一个用于安装项目依赖包的命令。其执行过程包括多个步骤,用于确保依赖包的正确下载、解析和安装。
1. 初始化
在执行 npm install 时,npm 首先会进行初始化,主要是解析项目目录中的 package.json 文件,读取其中的 dependencies 和 devDependencies 字段,确定要安装的包及其版本范围。
2. 确定依赖关系与版本
npm 会根据 package.json 文件中的版本要求(如 ^1.0.0、~2.1.5 等)确定每个依赖包的准确版本,同时解析各个依赖的子依赖关系。npm 通过查找 node_modules 缓存中的包或从注册源下载包来优化安装过程。
3. 获取包的完整信息
在解析包的版本和依赖关系后,npm 通过以下步骤获取完整的包信息:
- 锁定版本:如果项目包含
package-lock.json文件,npm 会优先根据该文件锁定版本。这可以确保团队成员或不同环境安装相同的依赖版本。 - 从缓存或仓库获取包:npm 会尝试从本地缓存中查找包;若缓存不存在或不可用,则从远程 npm 仓库下载对应包的
.tar.gz文件并缓存起来,以加快未来的安装速度。
4. 下载并解压包
npm 将每个需要安装的包下载到缓存中,并在下载完成后将 .tar.gz 文件解压缩至 node_modules 目录中。同时,npm 会为每个包检查其依赖并递归下载、安装这些子依赖包。
5. 创建 node_modules 树
在完成依赖包下载后,npm 会在项目的 node_modules 目录中创建符合依赖关系的目录树。npm 处理重复依赖的逻辑,尽量减少重复包,并根据需求决定包的嵌套深度。
6. 生成或更新 package-lock.json
安装结束时,npm 会根据实际安装的依赖包及版本生成或更新 package-lock.json 文件。package-lock.json 文件记录了所有安装包的精确版本、来源以及子依赖的具体版本,从而保证一致性。
7. 运行生命周期脚本
安装完成后,npm 会在 package.json 中查找并执行安装后相关的生命周期脚本,例如 postinstall、preinstall 等。这些脚本可以执行额外的设置或编译操作,例如安装完成后进行自动化测试、文件生成等。
总结
- 初始化:读取
package.json。 - 确定版本:锁定并解析依赖版本。
- 获取包:检查缓存或从仓库下载。
- 解压包:解压缩包文件到
node_modules。 - 构建树:处理依赖并创建目录结构。
- 更新锁文件:生成或更新
package-lock.json。 - 执行脚本:运行生命周期脚本(如
postinstall)。
通过这些步骤,npm 实现了包的高效安装,并确保项目环境的一致性。
使用案例: 要确保项目只能使用
pnpm安装依赖,可以在 package.json 中配置一个preinstall脚本,检测使用的包管理器是否是pnpm,如果不是则终止安装过程。具体步骤如下:
{
"scripts": {
"preinstall": "npx only-allow pnpm"
},
"devDependencies": {
"only-allow": "^2.0.0"
}
}18. 对 CSS 工程化的理解
CSS 工程化是指将传统的 CSS 开发模式转变为更结构化、模块化、可维护的方式,以便在大型项目中更高效地管理和维护样式代码。随着项目复杂度的增加,CSS 工程化变得尤为重要。
1. 模块化与组件化
CSS 工程化的一大核心思想是模块化与组件化,即将样式按照功能或模块拆分,而不是全局式的管理。通过将样式分解成小块并与特定组件绑定,减少全局污染,避免样式冲突。例如,利用 CSS Modules、BEM 命名规范、SCSS 的模块划分等方法实现样式的模块化。
2. 变量与预处理器
引入变量和预处理器(如 Sass、Less)使样式更加动态和灵活。可以定义全局变量(如颜色、字体大小等),并在整个项目中使用,确保一致性,也便于后期修改。
3. 构建与自动化
CSS 工程化通过构建工具(如 Webpack、Vite)自动化处理样式任务,例如压缩、添加浏览器前缀、代码拆分等。这不仅提高了性能,还简化了开发流程。
4. 样式隔离
在大型项目中,样式隔离是避免冲突的关键。可以使用 CSS-in-JS、Shadow DOM 或 Scoped CSS 等技术手段将样式与组件隔离,确保样式的独立性。
微前端当中也可以用使用:
postcss-prefix-selector类似的插件,添加额外的class类名
5. 响应式设计与适配
响应式设计是确保不同设备上样式一致性的关键。通过使用媒体查询、弹性布局(如 Flexbox、Grid)以及流体单位(如 rem、vw)等技术,可以实现良好的适配性。
6. 代码规范与文档
制定 CSS 代码规范,保证团队成员的一致性和代码可读性。可以通过注释、文档工具(如 Styleguidist、Storybook)记录样式使用方法,方便日后维护。
总结
CSS 工程化使得样式代码更易维护、可扩展,也更利于团队协作。在实际项目中,结合模块化、构建工具、响应式设计等技术手段,可以大大提升开发效率和样式质量。
19. Webpack 模块联邦(Module Federation)
Webpack 的模块联邦(Module Federation)是 Webpack 5 引入的一项新特性,旨在实现微前端架构下的模块共享和依赖管理,使不同的项目可以独立开发、部署并共享模块而无需打包重复代码。
模块联邦的核心概念
1. 主应用(Host)和远程应用(Remote)
模块联邦通常涉及多个应用间的模块共享关系:
- 主应用(Host):使用远程模块的应用,一般是一个容器或主项目。
- 远程应用(Remote):提供模块供其他应用引用的项目,通常可以是子应用。
2. 配置入口
在 Webpack 配置文件中,通过 ModuleFederationPlugin 插件定义主应用和远程应用的模块联邦配置:
- name:应用的唯一标识。
- filename:用于模块联邦的入口文件。
- exposes:暴露模块的路径和名称。
- remotes:定义需要加载的远程模块。
3. 动态加载
模块联邦支持动态加载远程模块,即在运行时从远程获取代码。这允许不同项目间的模块在无需重新构建的情况下共享和更新。
模块联邦的优点
- 独立开发和部署:各应用可以独立开发、更新,并可随时共享最新的模块,而无需重新构建其他应用。
- 避免重复代码:多个应用可以共享公共依赖,减少打包体积,提升性能。
- 运行时依赖共享:通过动态加载,应用可以在运行时获取依赖,保持代码一致性和及时性。
常见应用场景
- 微前端架构:多个独立应用可以在一个主应用中以模块方式集成,模块联邦有助于各团队独立开发、维护。
- 跨团队模块共享:在大型组织中,不同团队可以将自己的模块以联邦方式提供,供其他项目直接使用。
- 版本兼容管理:模块联邦允许共享和加载不同版本的依赖,有助于避免依赖冲突。
注意事项
- 性能问题:由于模块动态加载,可能会增加网络请求次数和延迟,需要优化加载策略。
- 版本管理:模块的版本和依赖关系需小心管理,避免不兼容的依赖引发错误。
- 跨域问题:远程模块通常通过 URL 加载,需确保相关服务器配置跨域支持。
模块联邦使前端架构的模块化、复用性大幅提升,为微前端架构提供了灵活高效的解决方案。
20. git rebase 与 git merge 的区别
git rebase 和 git merge 都可以将一个分支的更改合并到另一个分支,但它们的工作方式和结果不同。
1. git merge
git merge 是一种非破坏性的合并方式,会创建一个新的合并提交(merge commit),保留每个分支的提交历史。
操作方式:将目标分支与当前分支合并,生成一个合并提交。
特点:
- 保留完整的提交历史,适合需要查看分支变更记录的情况。
- 合并后历史中会包含多个父提交,生成的提交记录显示出“分叉”结构。
适用场景:适合团队协作,多个开发者并行开发的场景,便于保留和查看完整历史记录。
2. git rebase
git rebase 会将分支上的提交“平铺”到目标分支之上,重写提交历史,生成一个线性的历史记录。
操作方式:将当前分支上的提交重新应用到目标分支的最新提交之上,重写提交历史。
特点:
- 生成更简洁、线性的提交历史,便于查看。
- 不会产生合并提交,历史中不显示分支分叉。
- 是破坏性操作:会更改提交的 SHA 值,重写已推送到公共仓库的提交会引发冲突。
适用场景:适合个人开发,或需要清晰、线性的提交历史的场景。不适用于已推送到公共仓库的分支。
总结
git merge:适合团队协作,保留所有提交历史,记录中包含分支分叉和合并信息。git rebase:适合个人开发,提交历史更清晰,但重写历史可能导致冲突,不适合已推送的公共分支。
根据项目需求和协作方式,可以选择合适的操作方式。
21. git reset 与 git revert 的区别
git reset 和 git revert 都是 Git 中用于撤销提交的命令,但它们的工作方式和适用场景有所不同。
1. git reset
git reset 是一种本地操作,可以重置项目的历史状态,将当前分支指针移回到指定的提交位置,并丢弃其后的提交记录。git reset 是破坏性的操作,适合用于本地代码调整。
常用模式:
--soft:仅移动 HEAD 指针,保留提交的内容在暂存区,适合重新组织提交。--mixed(默认):移动 HEAD 指针并清除暂存区内容,代码文件保留在工作区。--hard:移动 HEAD 指针,清除暂存区及工作区内容,将代码回退到指定提交的状态。
特点:
- 修改历史记录,是破坏性操作,通常不适合已推送的远程分支。
- 更适合本地开发中需要重置或清理提交记录的场景。
适用场景:在本地开发时,撤销最新或一系列提交,以重新组织或优化提交历史。
2. git revert
git revert 是一种非破坏性的撤销方式,通过创建一个新的提交来抵消指定的历史提交,从而实现“撤销”的效果。适用于需要保持历史记录完整的场景。
- 操作方式:生成一个新的提交,将指定提交的更改反向应用,保留了历史记录。
- 特点:
- 不
22. git cherry-pick 命令
git cherry-pick 是 Git 中用于挑选特定提交并将其应用到当前分支的命令。它允许你从一个分支中选择一个或多个特定的提交,将这些提交应用到另一个分支,而不是合并或重置整个分支。
使用场景
git cherry-pick 适用于以下场景:
- 挑选某个功能或修复:当你只需要将某个特定提交(比如 bug 修复)从一个分支移植到另一个分支时。
- 避免合并其他不需要的提交:只将需要的提交挑选过来,避免不必要的提交被合并进来。
基本概念
- 挑选提交:
git cherry-pick会将指定的提交应用到当前分支。 - 批量挑选:可以一次性挑选多个提交,或者选择一个提交范围。
- 解决冲突:如果在应用提交时出现冲突,Git 会提示解决冲突,解决后继续应用提交。
git cherry-pick 的注意事项
- 破坏性:
git cherry-pick会将提交应用到当前分支,可能导致目标分支的提交历史发生变化,但不会修改原始提交的历史。 - 历史重写:如果
cherry-pick提交的内容已经存在,可能会产生额外的合并提交或冲突。 - 避免滥用:频繁使用
cherry-pick可能会使得提交历史变得混乱,难以追踪代码的变化。
总结
git cherry-pick允许从一个分支中挑选特定提交,并将其应用到当前分支,适用于需要从其他分支移植特定修复或功能的场景。- 与
git merge或git rebase不同,cherry-pick仅针对单个提交,避免了将多个不需要的提交合并进来。
23. git fetch 与 git pull 的区别
git fetch 和 git pull 都用于从远程仓库获取更新,但它们的操作方式和结果不同。
1. git fetch
git fetch 是一种安全的获取远程仓库更新的方式,它从远程仓库下载所有最新的提交和数据,但不会自动合并到当前分支。
操作过程:
git fetch会获取远程仓库的更新数据,但不会改变本地分支。你需要手动将更新的内容合并到本地分支。特点:
- 不会改变工作目录或本地分支。
- 只会获取更新的对象,如提交、分支等,不会执行合并操作。
- 允许查看远程仓库的更改,但需要手动决定是否合并这些更改。
适用场景:当你希望查看远程仓库的新提交,并且希望在决定合并之前先查看差异时,使用
git fetch。
2. git pull
git pull 是git fetch 和 git merge 的组合命令,它不仅从远程仓库获取更新,还会自动将这些更新合并到当前分支。
操作过程:
git pull会先执行git fetch,然后自动将远程仓库的更新合并到当前分支。如果存在冲突,Git 会提示解决冲突。特点:
- 会自动合并远程分支的更改到当前分支。
- 更加简洁,适合快速同步远程和本地的状态。
- 如果本地和远程分支有冲突,Git 会要求解决冲突并完成合并。
适用场景:当你希望直接将远程仓库的更新合并到本地分支时,使用
git pull。
总结
git fetch:只从远程仓库获取更新,但不合并。适合先查看远程更改,决定是否合并。git pull:从远程仓库获取更新并自动合并。适合直接同步远程分支的最新状态。
使用 git fetch 可以让你更有控制地进行操作,而 git pull 则更快速、直接地同步本地和远程的更改。